

Create a value exchange with Tapjoy

Advertising should be a value exchange. The Tapjoy offerwall connects top advertisers with premium publishers and then rewards mobile users for their time. Now that’s a win-win.
Partnered with the best

For developers
Maximize app revenue with the Tapjoy offerwall
Roughly 15% of the top 100 grossing apps use offerwalls. That figure expands to 25% for top-grossing mobile games. Tapjoy is the industry leader in the offerwall category, with eCPMs for Android in the US exceeding $1,000. Plus, Tapjoy’s fully custom, native offerwall deployments that drive up to 30% more revenue than generic alternatives.
Get startedGet started
For advertisers
Acquire and engage users at scale with an offerwall campaign
On the Tapjoy offerwall, users have the choice to voluntarily engage with ads that interest them in exchange for a reward. The result is that your best users come to you.
Learn about CPELearn about CPE Learn about CPALearn about CPA
Integrate the Tapjoy ad network
The Tapjoy ad network connects publishers with premium demand sources. Our solutions will help you monetize every user to their maximum potential.
Get startedGet startedWhat our customers are saying

Daphne Li, User Acquisition Director at Funplus
“Pay per event brings us better user retention and ROAS, It’s working so wonderfully for our games and we will always consider Tapjoy a top partner.”
View case studyView case study
Alexander Jorias, CEO & Co-Founder at Club Cooee
“Tapjoy currency sales provide a great way for us to boost ad revenue. In the last sale, we achieved an impressive 3.6x increase in revenue and a nearly 4x increase in conversion rate”
View case studyView case study
Magda Z, Senior User Acquisition Manager at Huuuge Games
“CPE is one of our most effective and high performing ad units when it comes to ROAS. Multi-Reward CPE also allows us to scale our UA campaigns while reducing the number of live offers we have to manage day-to-day.”
View case studyView case study
Rohan Panjiar, Director of Performance Marketing at Winc
“With Tapjoy, we were able to scale our DR offer for the 21+ audience AND keep our CPS in target range while improving our LTV.”
View case studyView case studyExpert insights to supercharge your offerwall strategy

How Appynation optimized the Tapjoy Offerwall, multiplying iOS revenue 9x and increasing Android revenue 2x without cannibalizing IAP
Read more >>
How MY.GAMES transformed their monetization strategy and expanded their global reach with Tapjoy, increasing their Offerwall revenue by 181% without sacrificing any IAP revenue
Read more >>
How King drove incremental scale with Tapjoy from Unity's Daily Rewards, exceeding their D7 ROAS goal by 1.5x
Read more >>
Tapjoy from Unity launches Daily Rewards, delivering Offerwall campaigns that bring users back to your app daily
Read more >>
How Pocket FM monetized their non-paying users with ads and offerwall, boosting revenue 20%
Read more >>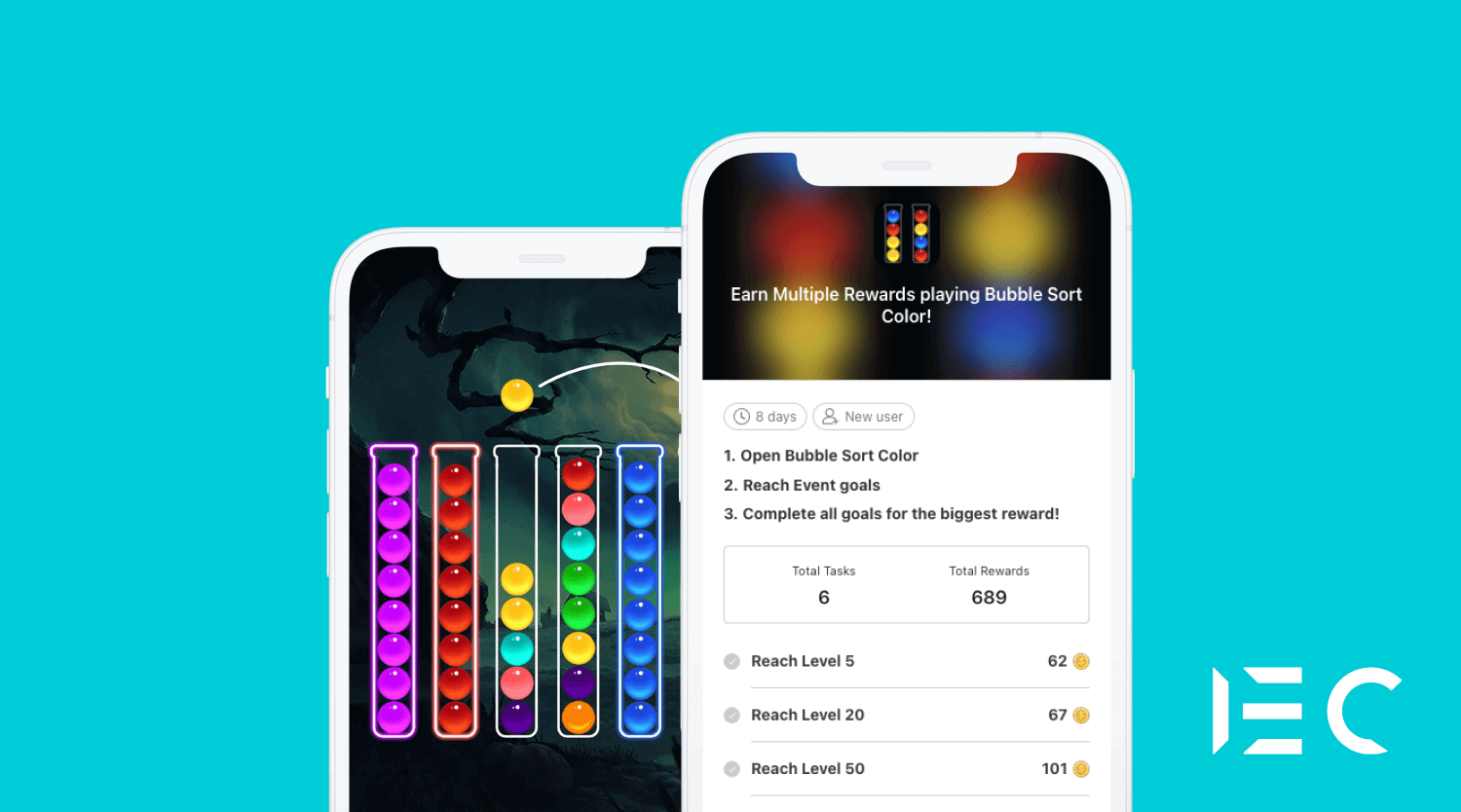
How IEC Games, a hyper-casual publisher, boosted their D7 ROAS by 40% with the Tapjoy offerwall
Read more >>


How to maximize growth with offerwall special promotions: tips for the holiday season
Read more >>
How Ok Cashbag & Syrup boosted their revenue 63% with Unity LevelPlay mediation and 225% with the Tapjoy offerwall
Read more >>
How Big Fish Games boosted their offerwall revenue 96% and IAP ARPDAU by 10% with the Tapjoy offerwall
Read more >>